
In this project I have tried mainly answer 2 questions.
-
Part1: To predict the Salary from the details we have like title, location, classification/industry and the skills or words from the Job Description.
-
Part2: To predict whether job title is Data Scientist/Analyst or others from the skills and key words in Job Description.
Approach:
Here I have scrapped more than 1000 data points and details from Seek.com with the keywords Data scientist, Data analyst, Business intelligence, Business analyst from 3 different cities which are Melbourne, Sydney and Brisbane.
After scrapping the data I have cleaned it according to industry standards and since a lot of records did not had salary data I have selected only records with salary data for the first part so that I can make a better model. While I have used the entire dataset for part 2 since salary was not involved in it anyways.
Methods
I have scrapped the data and made a CSV file from it for further use in the project.
Part1: I have selected the salary prediction as a classification problem and from the known data, created a new feature to tell me whether it is a high paying job or low paying and set the limit as 115,000 after analysing the existing data. I have used Logistic Regression, then with a grid search selected “l2” penalty or Ridge as a feature selection. With ridge feature selection, I used Logistic regression. Then I tried another another model decision tree as classifier so that I could confirm or upgrade my model. From these two models, I found the key skills/buzz words and features that mostly affected the salary.
Part2:
I have implemented 2 models to predict whether the job is in relation to Data Scientist/Analyst from JD. I have used a pipeline to implement those models and used count vectorization as one of the main tools for predictions. I have implemented Naive Bayes method and Logistic regression to predict the title. I have done a proper stop word implementation to get a better prediction and it worked well in this case.
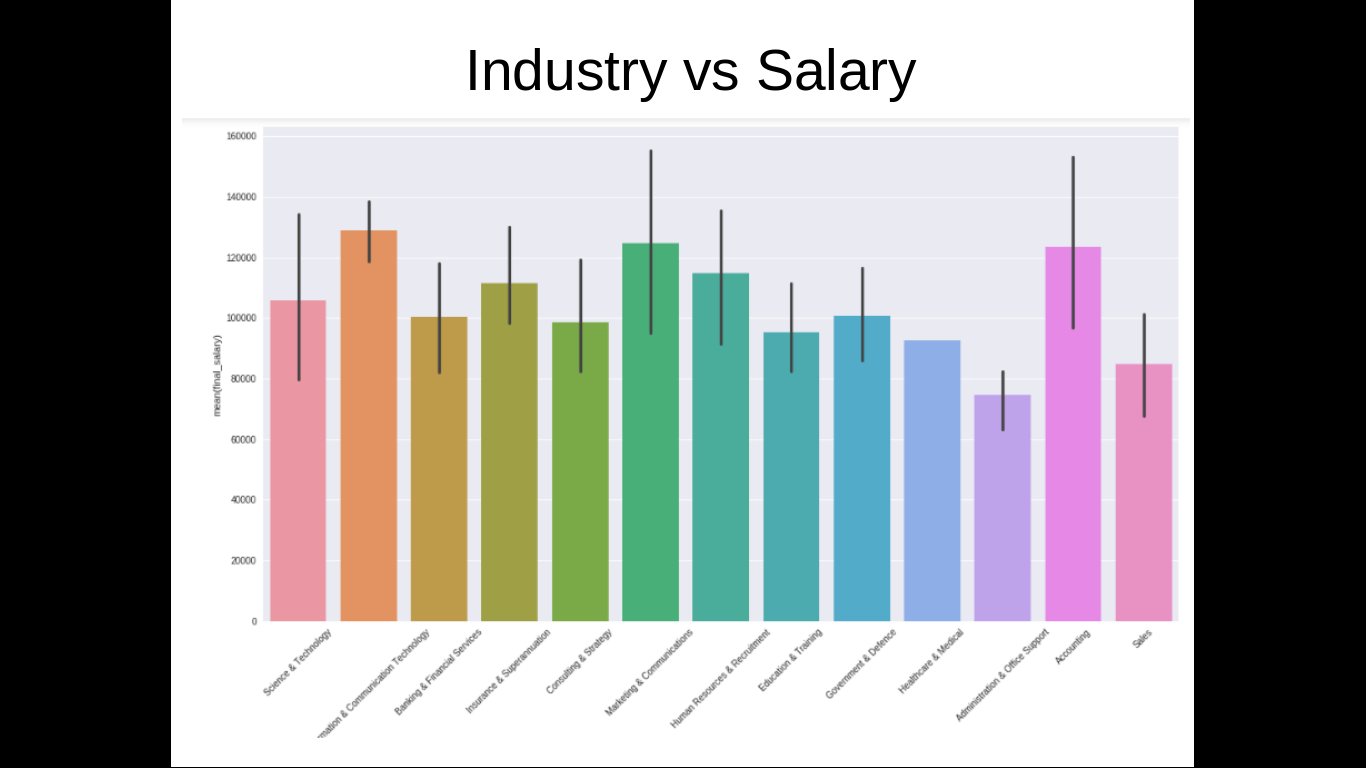 Above figure shows the mean salary towards each industry
Above figure shows the mean salary towards each industry
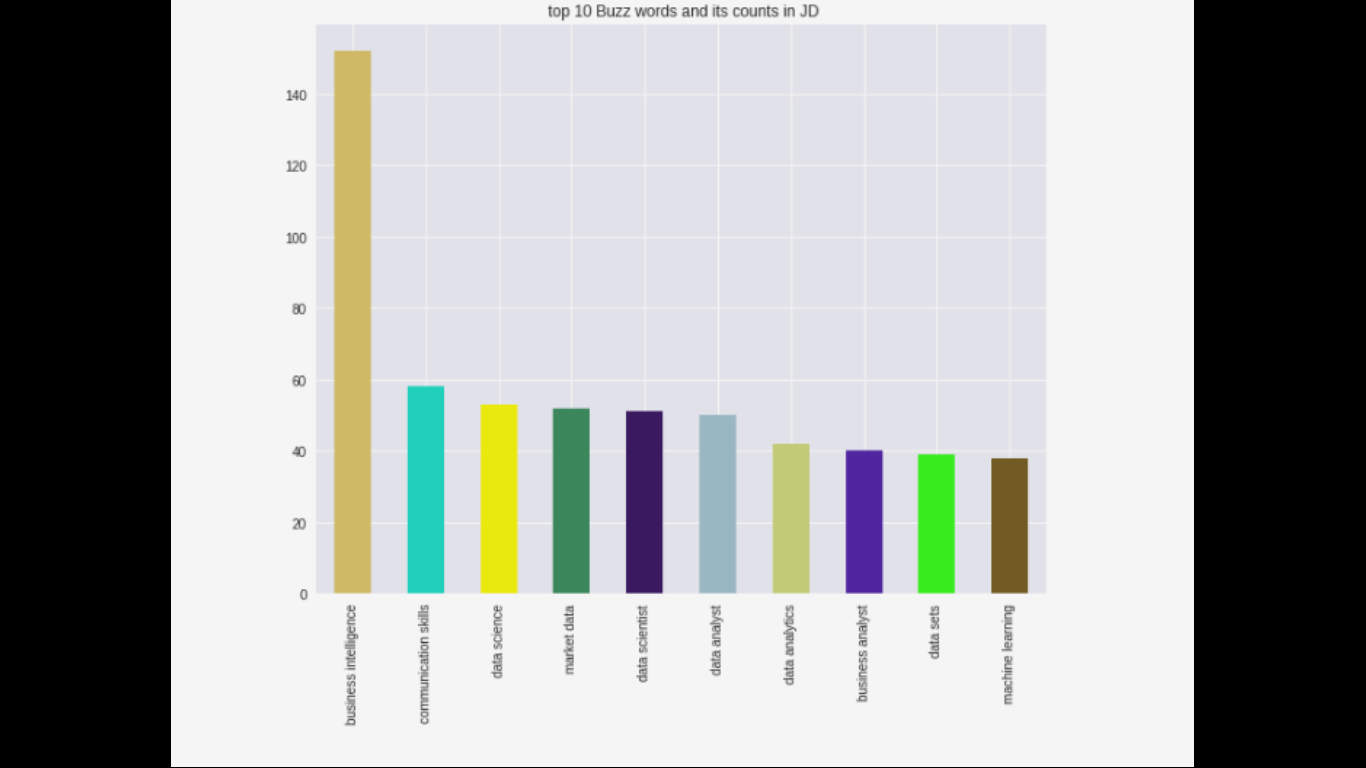 Above figure shows the top 10 keywords and its counts in the Job Description provided.
Above figure shows the top 10 keywords and its counts in the Job Description provided.
Inference
Part1: From the 2 models I have implemented and tested some of the main features that directly affect salary are classification/ industry of job, which include Information & Communication Technology, Consulting & Strategy, Education & Training, Marketing & Communications. It also shows that location has an impact. If we look through the key words or group of words that have impact on Salary some of them are “business intelligence”, “big data”, “business development”, “advanced analytics”, “data analysis”, “data driven”, “high performing”.
Part2: Here I have tried to predict whether a job title is Data scientist/Analyst from the job description. I implemented 2 models Naive Bayes Classifier and Logistic Regression. I tried implementing the model with 20% test data and with full dataset as well. For both models ROC and classification report seem to be great. Both the models seems to be good and can also be used for predicting the title with the JD’s for further scrapping or for internal use.
Conclusion
Part1: Here I have implemented mainly 2 models to make it a classification problem. High and low salary implementing mainly two models, logistic regression and a decision tree. Both the classification seems to be a good predictor with approximately 75% area in ROC curve. From both the models I have found out the key skills and features that are related to the salary. Part2: I again checked through 2 models and the prediction through the job description worked well.
